
[C++] 类和对象(2): 默认成员函数介绍分析、构造函数、析构函数、拷贝构造...
一、类的默认成员函数
- 构造函数
- 析构函数
- 拷贝构造函数
- 赋值重载函数
- 普通对象取地址重载函数
- const修饰的对象取地址重载函数
二、构造函数

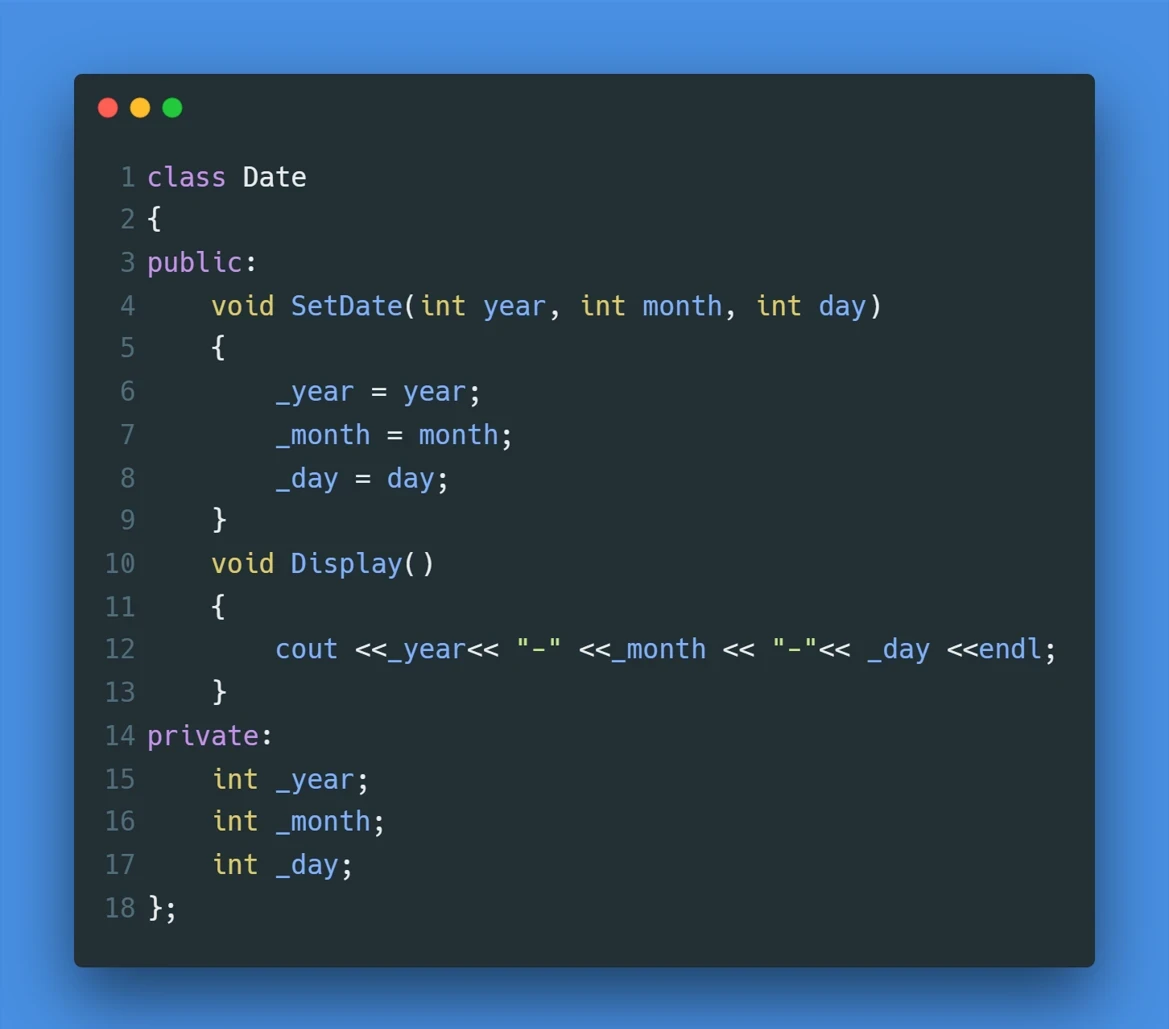
void SetDate:是给 对象 设置日期内容的成员函数。构造函数 就可以很好的解决这个问题。构造函数 是一个特殊的成员函数,函数名与类名相同,没有返回值,在创建对象时编译器会自动调用构造函数,来对对象进行 ”初始化” 操作2.1 构造函数的特性
构造函数 是特殊的成员函数,它的作用并不是构造、创建一个对象,而是初始化对象。-
函数名与类名相同
-
没有返回值
以 日期类 为例,
class Date的构造函数名,就为Date()![]()
-
对象实例化时,
由编译器自动调用给构造函数添加内容:
![]()
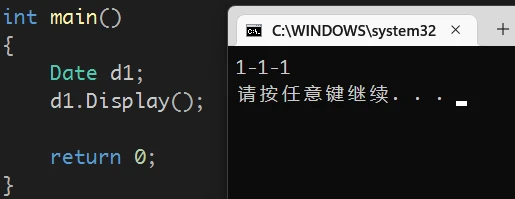
创建对象,并查看对象:
![]()
对象d1已经按照构造函数初始化在定义一个对象时,构造函数自动执行,
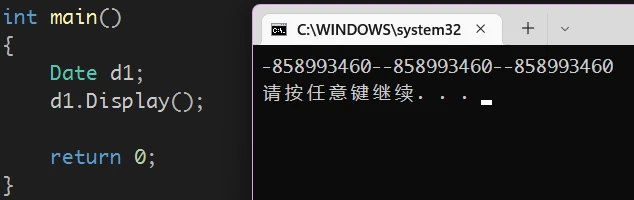
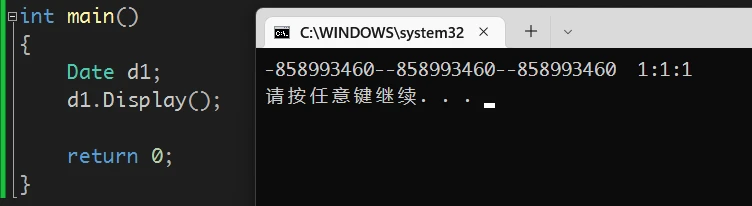
对象d1内容被初始化如果构造函数无内容(无显式构造函数),那么:
![]()
对象d1将是随机值虽然构造函数被调用了,但是并没有处理数据(原因查看第5、6、7条特性)
-
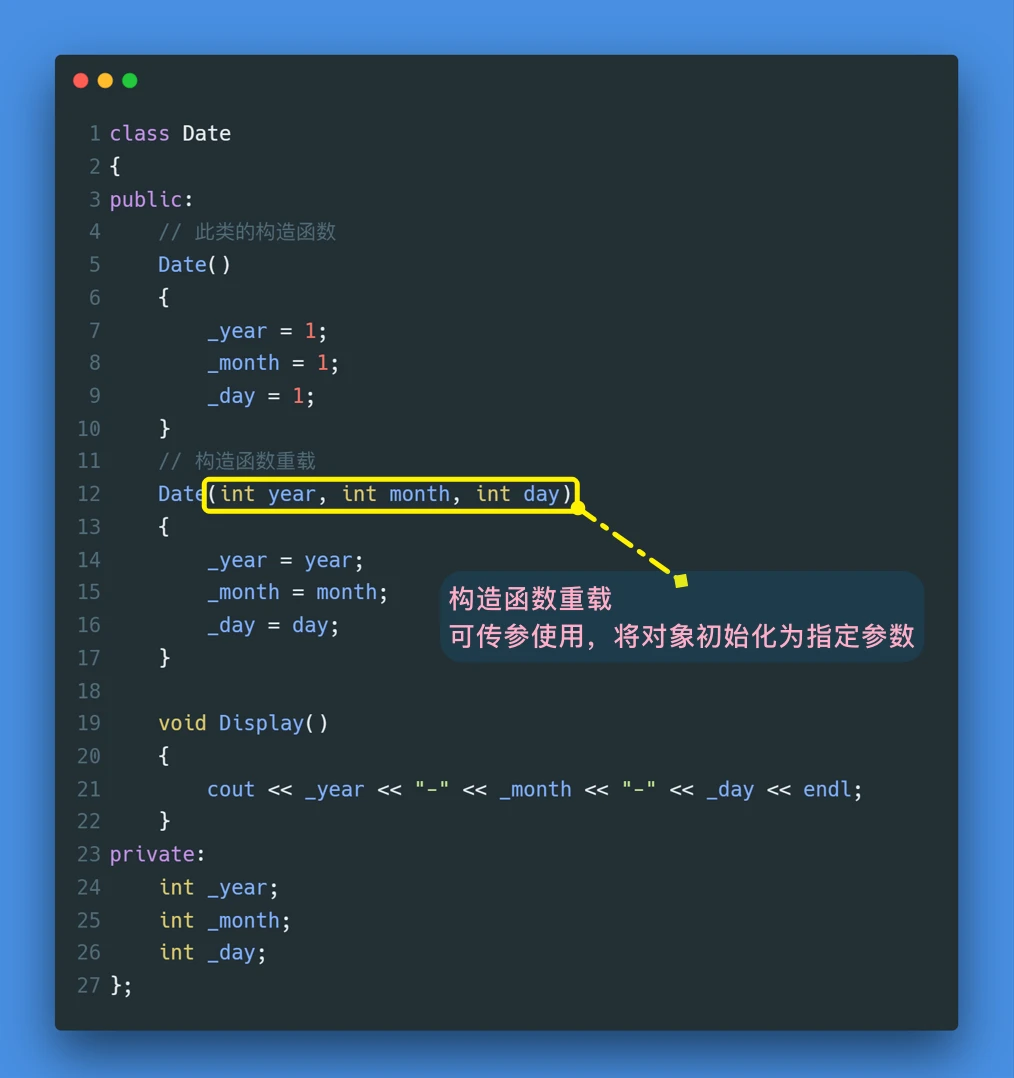
构造函数可以重载
构造函数可以重载就意味着,构造函数其实可以传参使用同样以日期类为例:
![]()
对于重载的构造函数,传参使用是这样使用的:
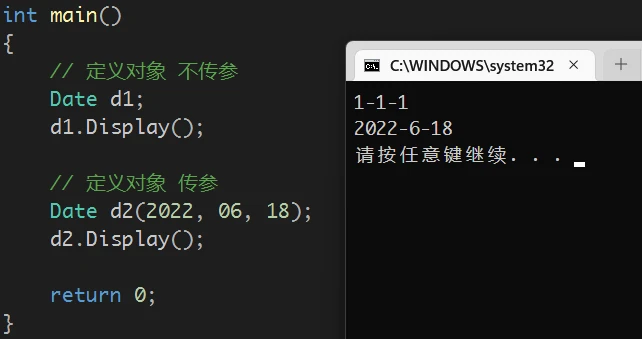
// 定义对象 不传参 Date d1; d1.Display(); // 定义对象 传参 Date d2(2022, 06, 18); d2.Display();![]()
既然可以传参使用,那么就涉及另一个运用:
缺省参数对于构造函数,
无论是函数重载、全缺省参数还是半缺省参数,都是可以运用的 -
C++编译器会自动生成一个无参的默认构造函数
一个类中,如果没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数;一旦用户显式定义,编译器将不再生成。意思就是,如果构造函数被编写出来了,编译器将不自动生成
无参默认构造函数 -
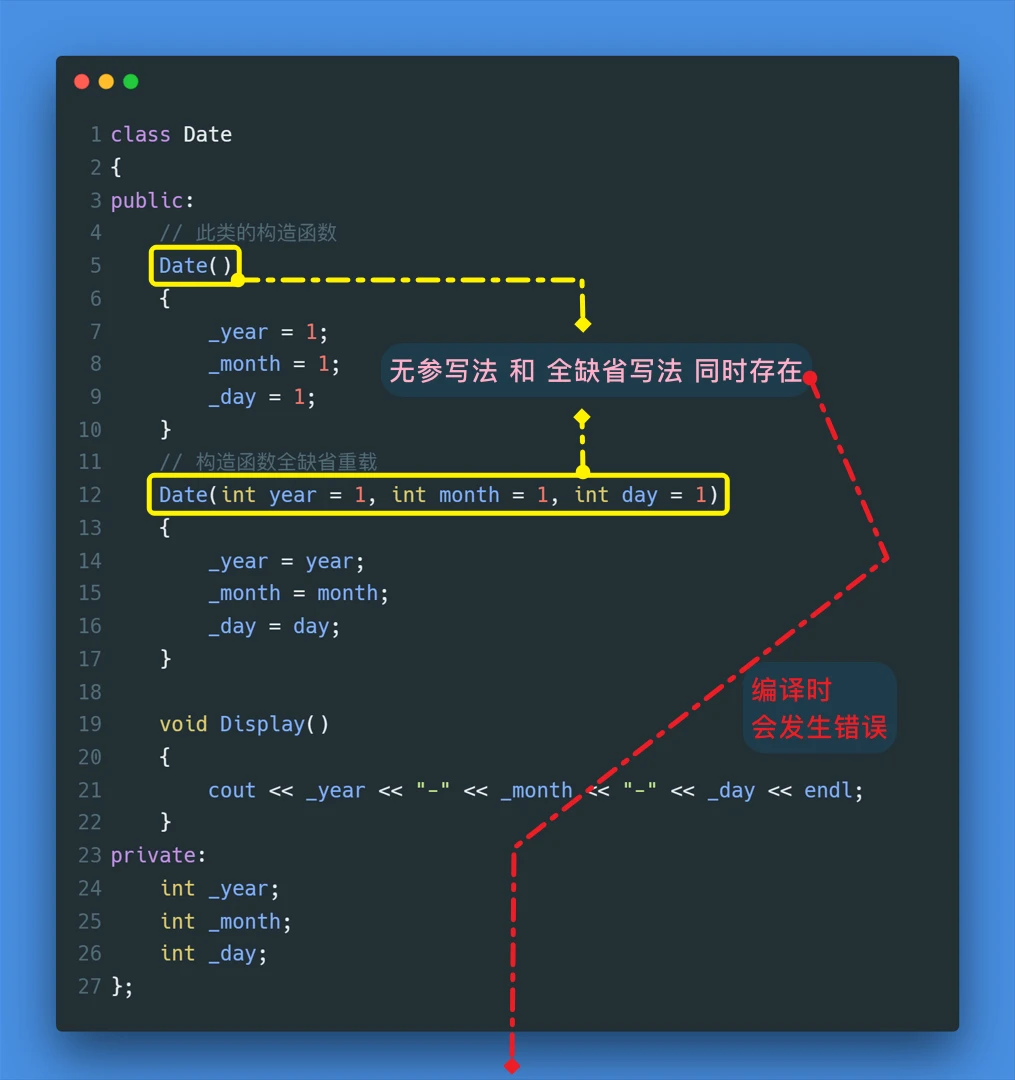
默认构造函数
无参的构造函数 和 全缺省的构造函数 都称为默认构造函数,
默认构造函数只能有一个。注意:无参构造函数、全缺省构造函数、编译器默认生成的构造函数,都可以认为是默认构造函数
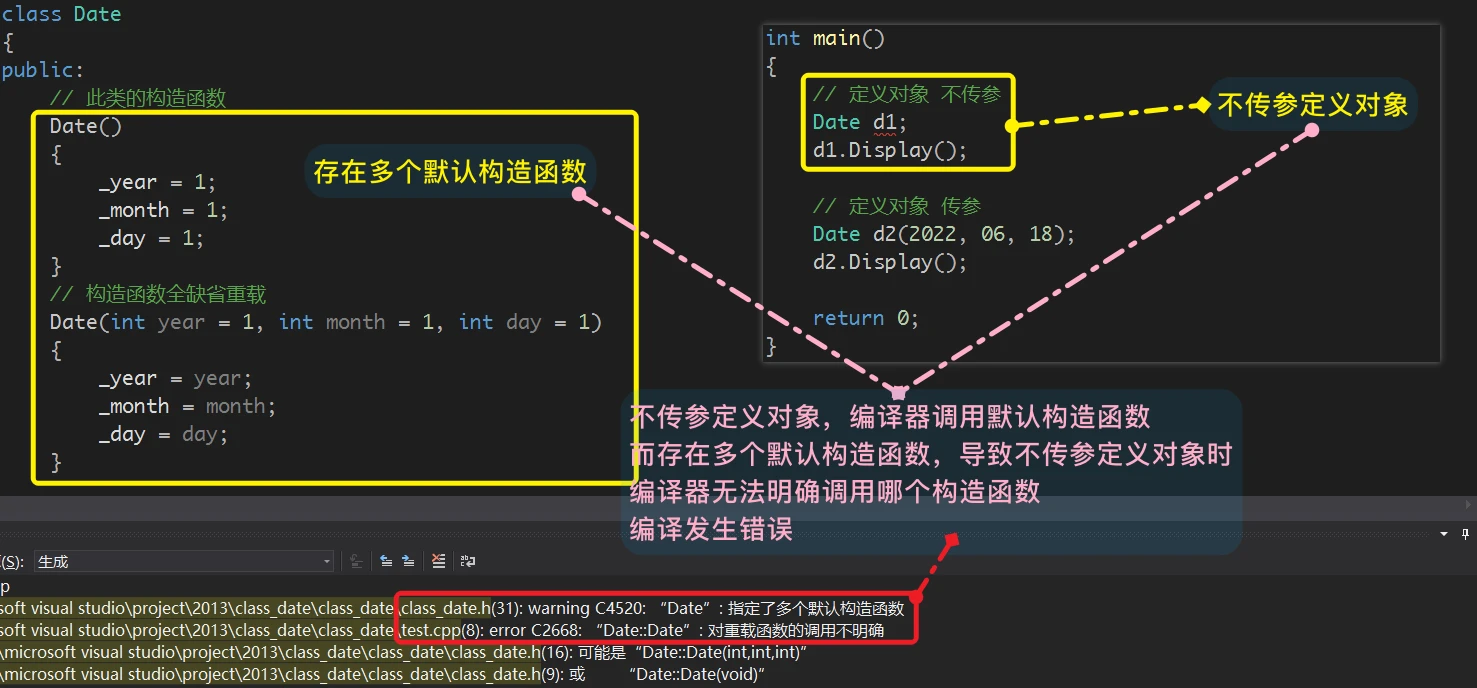
(对象实例化时不传参自动调用的,就被称为默认构造函数)一个类中,默认构造函数只能存在一个,是什么意思呢?
显式定义构造函数时,一般有三种方式:
无参数定义,全缺省参数定义,半缺省参数定义、有参数定义而无参构造函数 和 全缺省构造函数 是默认构造函数,这两种写法是不能同时存在的
![]()
![]()
-
构造函数的数据处理特性
C++ 规定:编译器生成默认的构造函数, 对
内置类型数据(int、char、double……等) 不做处理;对自定义类型数据(class、struct、union等自定义的),调用 其类的默认构造函数 进行处理以下面的 日期类包含时间类 为例:
![]()
使用以上日期类定义对象,并且输出日期类 对象内容:
![]()
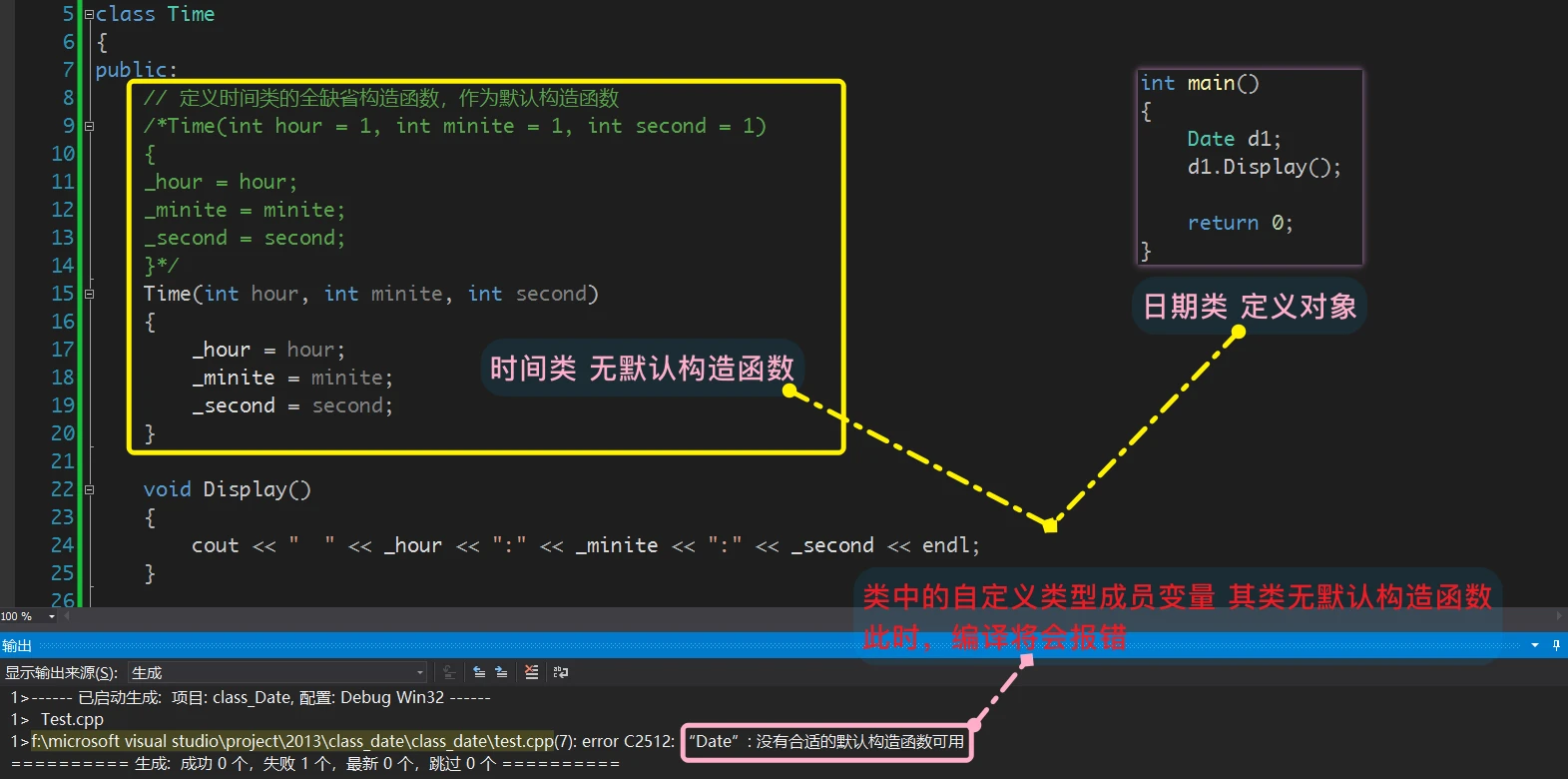
内置类型成员数据没有处理,自定义类型成员数据 调用其类的默认构造函数处理。但是,如果 自定义类型成员没有默认构造函数,则会发生报错:![]()
结论就是,编译器自动生成的默认构造函数, 对
内置类型数据(int、char、double……等) 不做处理;对自定义类型数据(class、struct、union等自定义的),调用 其类的默认构造函数 进行处理

.webp)
.webp)
2.2 构造函数的使用
全缺省构造函数 的形式。全缺省构造函数,可以传参、也可以不传参、同时还是默认构造函数没有显式构造函数时,编译器自动生成的无参默认构造函数
并不是没有用例如:利用 栈与队列 互相实现时,编译器自动生成的无参默认构造函数就很有用
三、析构函数
析构函数 的作用恰巧与 构造函数 相反。析构函数是在对象销毁时,清理数据用的。析构函数不是完成对象的销毁对象在销毁时自动调用析构函数,对类的一些资源进行清理.webp)
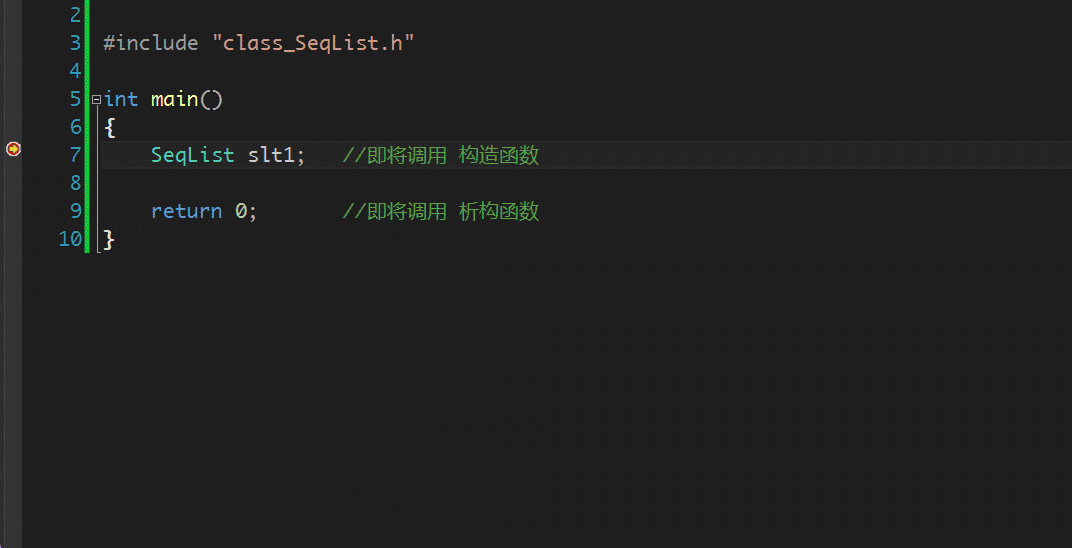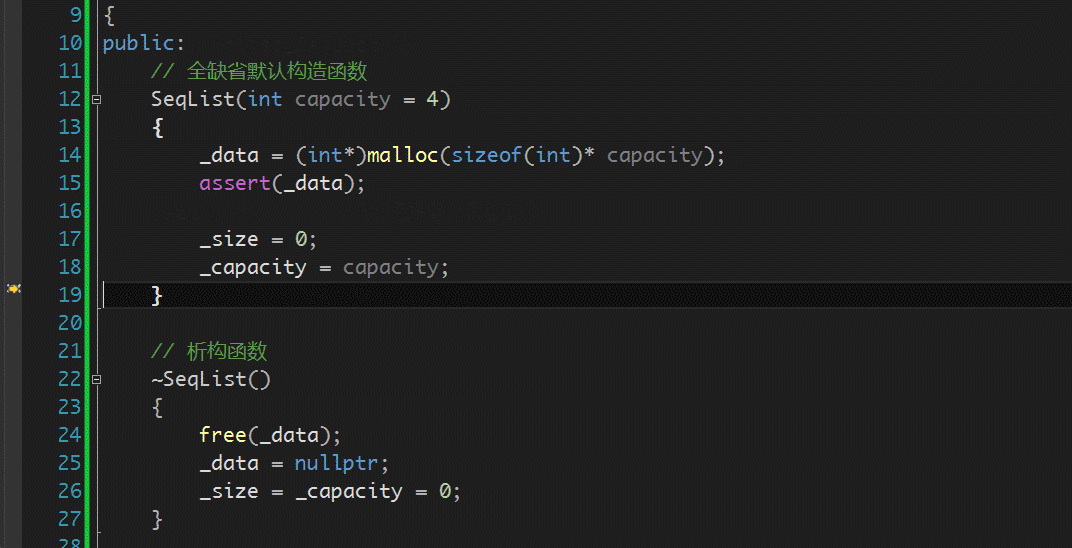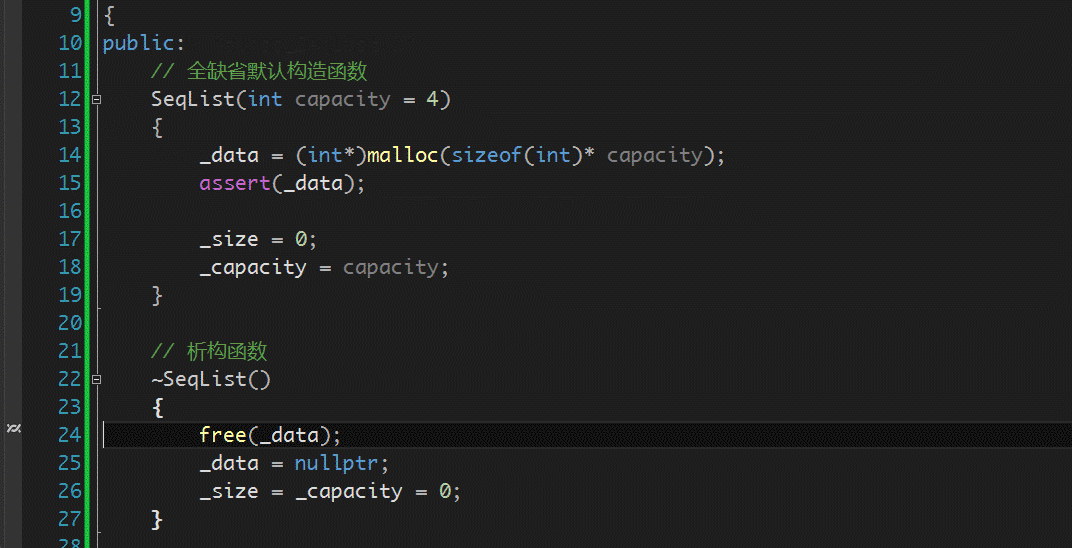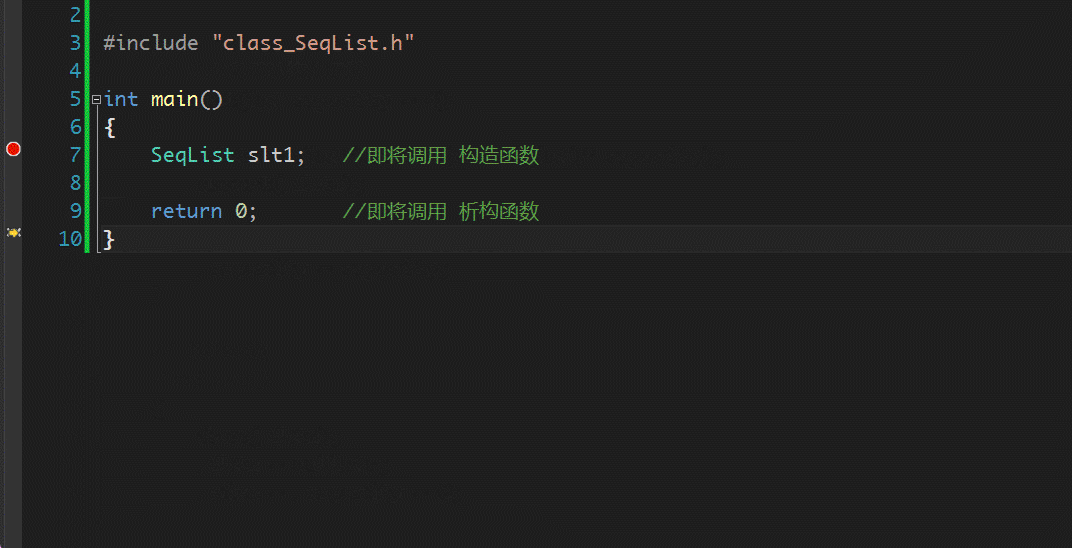
~SeqList 即为此类的析构函数。析构函数到底有什么作用呢?什么是资源清理?int main()
{
SeqList slt1;
return 0;
}
在程序还未结束,但是对象的生命周期快要结束时,对 对象的数据进行了清理,并且没有销毁对象析构函数的作用就是 清理对象数据,并不涉及对象的销毁3.1 析构函数的特性
-
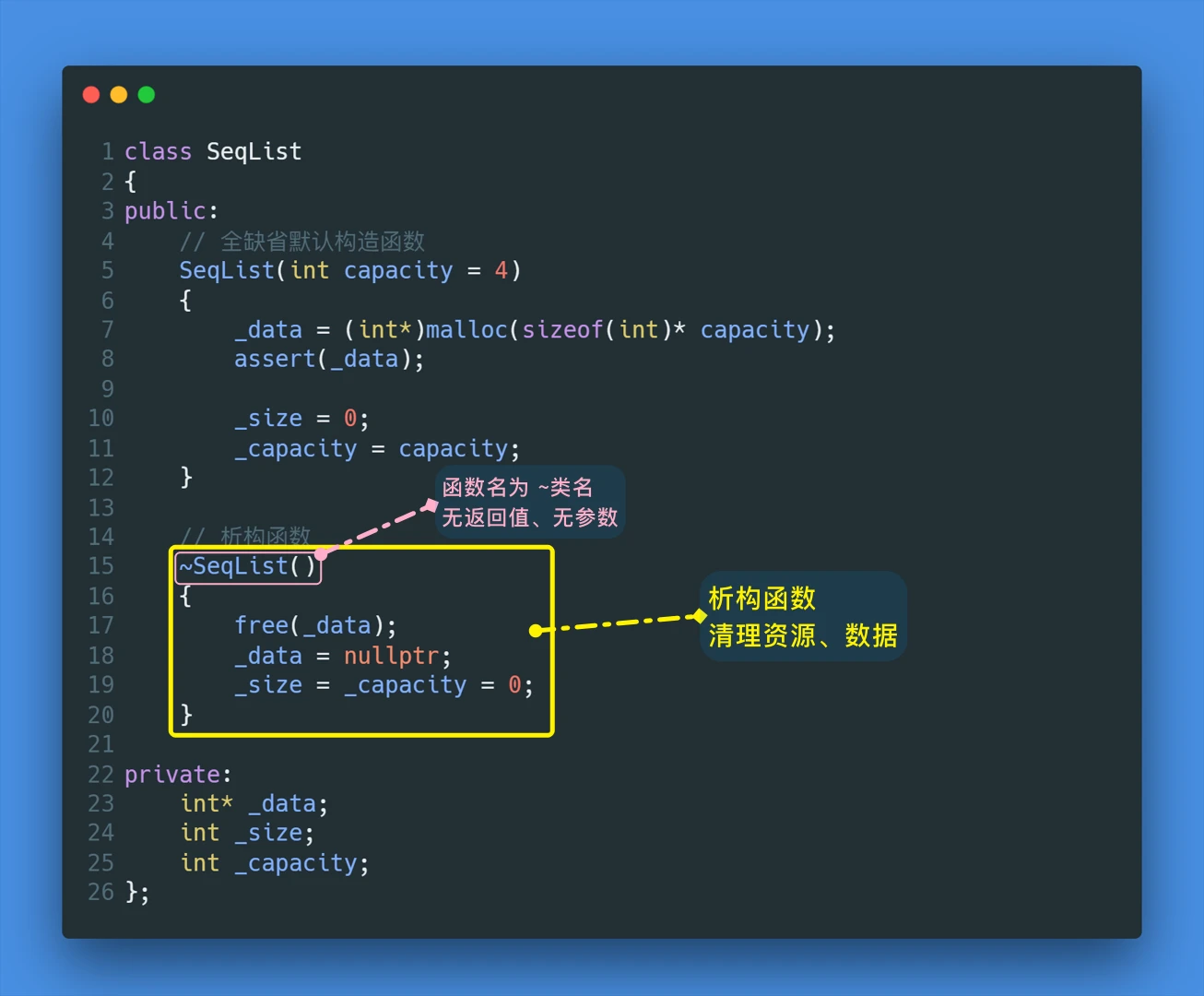
函数名为:~类名
-
无参数且无返回值
以顺序表类为例,其析构函数需写为:
![]()
-
一个类,有且只有一个析构函数
不同于构造函数,由于析构函数规定无参,所以一个类只能存在一个析构函数
-
无显式定义析构函数时,编译器自动生成析构函数
-
对象生命周期结束时,编译器自动调用析构函数
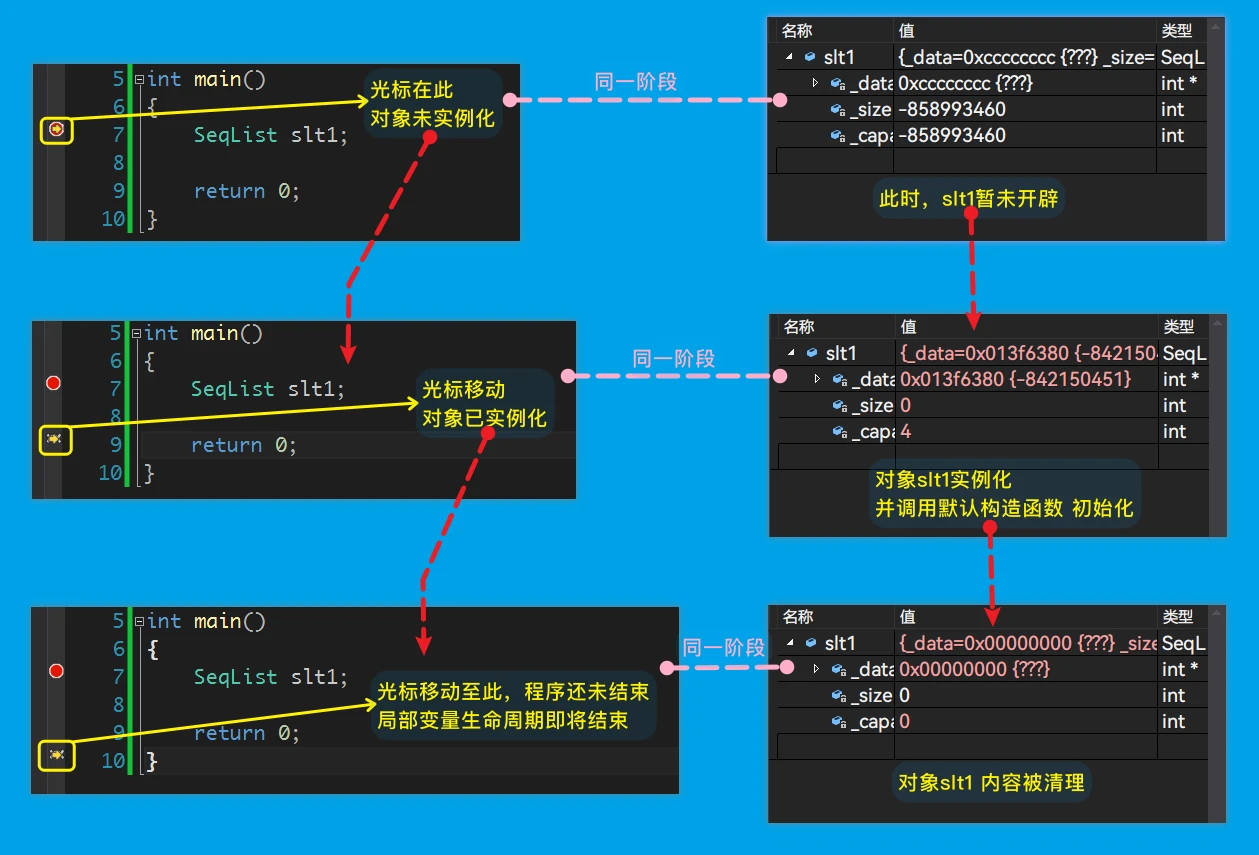
以下动图是创建对象、调用构造函数、调用析构函数、对象生命周期结束的过程
![class]() class
class当
对象slt1声明周期即将结束时,指令光标继续移动就会自动调用析构函数,清理对象数据、资源 -
C++编译器会自动生成一个析构函数
与 构造函数相似,
析构函数没有显式定义时,编译器会自动生成一个析构函数并且,编译器**
自动生成的析构函数**,处理对象数据时,同样对内置类型不做处理,对自定义类型则调用此自定义类型的析构函数进行处理(过程与编译器自动生成的默认构造函数相似)
3.2 不同对象 调用析构函数的顺序
析构函数 还有一点非常的重要:一个程序中,不同的对象 调用析构函数的顺序是什么?SeqList slt1; // 全局对象
int main()
{
SeqList slt2; // 局部顺序表对象
Date d1; // 局部日期对象
static Date d2; // static修饰的对象
return 0;
}(注意右方监视对象的变化):
main 函数内部的局部对象(slt2 和 d1):对象slt2 先被实例化,并调用构造函数;对象d1 后被实例化,并调用构造函数
但是在 两对象生命周期即将结束时
对象d1 先调用析构函数;对象d1 后调用析构函数(slt1 和 d2):对象slt1 先被实例化,并调用构造函数;对象d2 后被实例化,并调用构造函数
程序 从main函数出来后,光标继续移动时
并没有观察到右边 static修饰的对象d2 的变化,只观察到了全局对象 slt1的变化;只观察到了
全局对象 slt1变化的原因应该是: 因为main函数已经结束了,已经无法查看main函数内的对象; 而对象d2虽然用static修饰了,但是 它是在main函数内定义的 所以,VS 右方监视窗口无法观察到变化
main函数时,指令光标 先进入了 Date类(对象d2所属类)的析构函数当中,然后再是 全局对象slt1 调用了析构函数
其实,先进入的 Date类 析构函数这个过程,就是 对象d2 调用其析构函数的过程
也就是说, static修饰的对象d2 先调用析构函数, 全局对象slt1 后调用析构函数先调用构造函数的对象,后调用析构函数。这个过程 优点类似于函数栈帧的开辟与销毁对象调用析构函数的顺序,其实是对象调用构造函数顺序的倒序四、拷贝构造函数
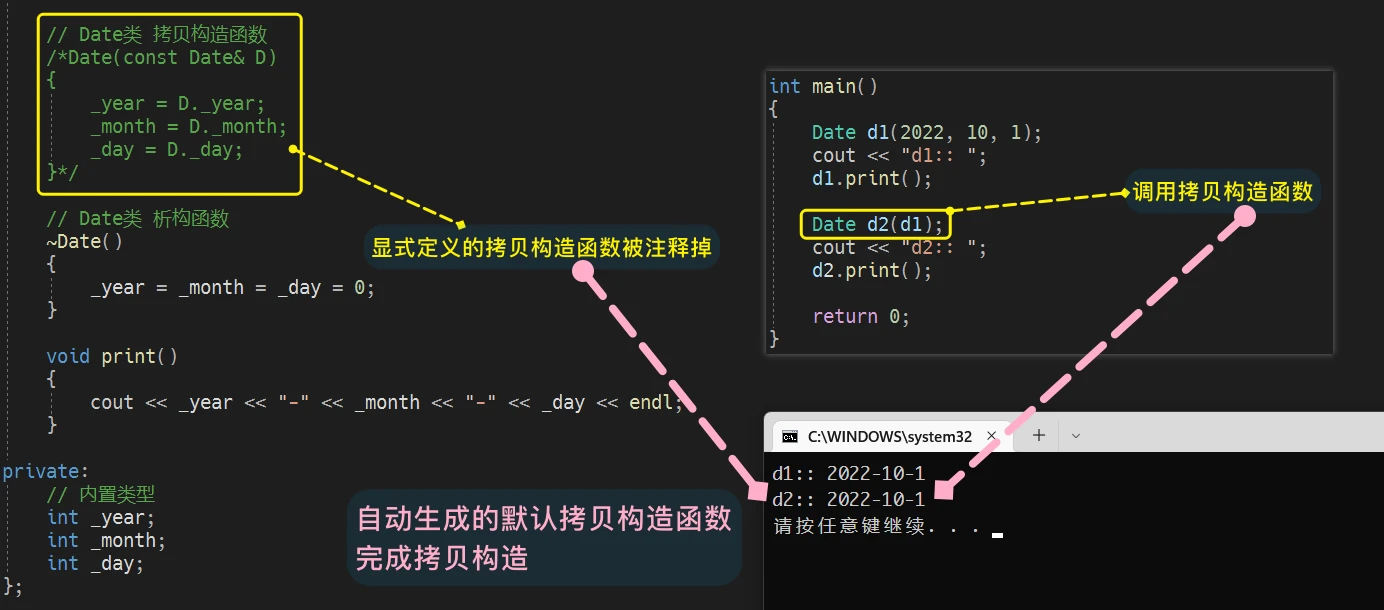
构造函数和析构函数拷贝构造函数拷贝构造函数 的作用就是拷贝,将已有的对象的内容拷贝至另一个对象,使两对象内容相同.webp)
对象d1 拷贝至 对象d2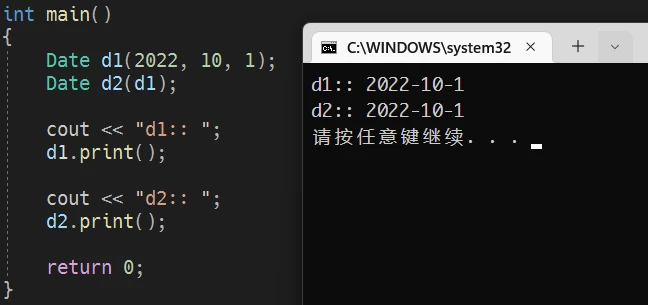
4.1 拷贝构造的特性
-
拷贝构造函数是构造函数的重载
-
拷贝构造函数有且只有一个参数,且参数类型只能为 类的引用
为什么
参数类型只能是类的引用呢?是因为,如果是
传值传参,将会引发无限递归导致程序崩溃为什么会无限递归?因为,函数的传参其实是原数据的临时拷贝,所以类的传值传参需要调用拷贝构造函数,来对 对象进行拷贝
如果 拷贝构造函数使用了传值传参,那么就会造成: 调用拷贝构造需要传值传参 ---> 传值传参需要调用拷贝构造 ---> 调用拷贝构造需要传值传参 ---> 传值传参需要调用拷贝构造……
就会发生无限递归
为什么不用指针传参?使用了指针传参,就不是拷贝构造函数了,拷贝构造函数的功能是:
对象的内容拷贝到另一个对象;而不是指针指向的内容拷贝到另一个对象![]()
-
无显式定义拷贝构造函数时,编译器自动生成拷贝构造函数
默认拷贝构造函数,按内存存储、按字节序实现拷贝。即,依照内存存储中,一字节一字节的直接拷贝。 这种拷贝方式被称为:
浅拷贝、值拷贝![]()
浅拷贝是可以在在一定程度上完成一些拷贝构造的但是
浅拷贝有非常大的弊端 -
浅拷贝的弊端
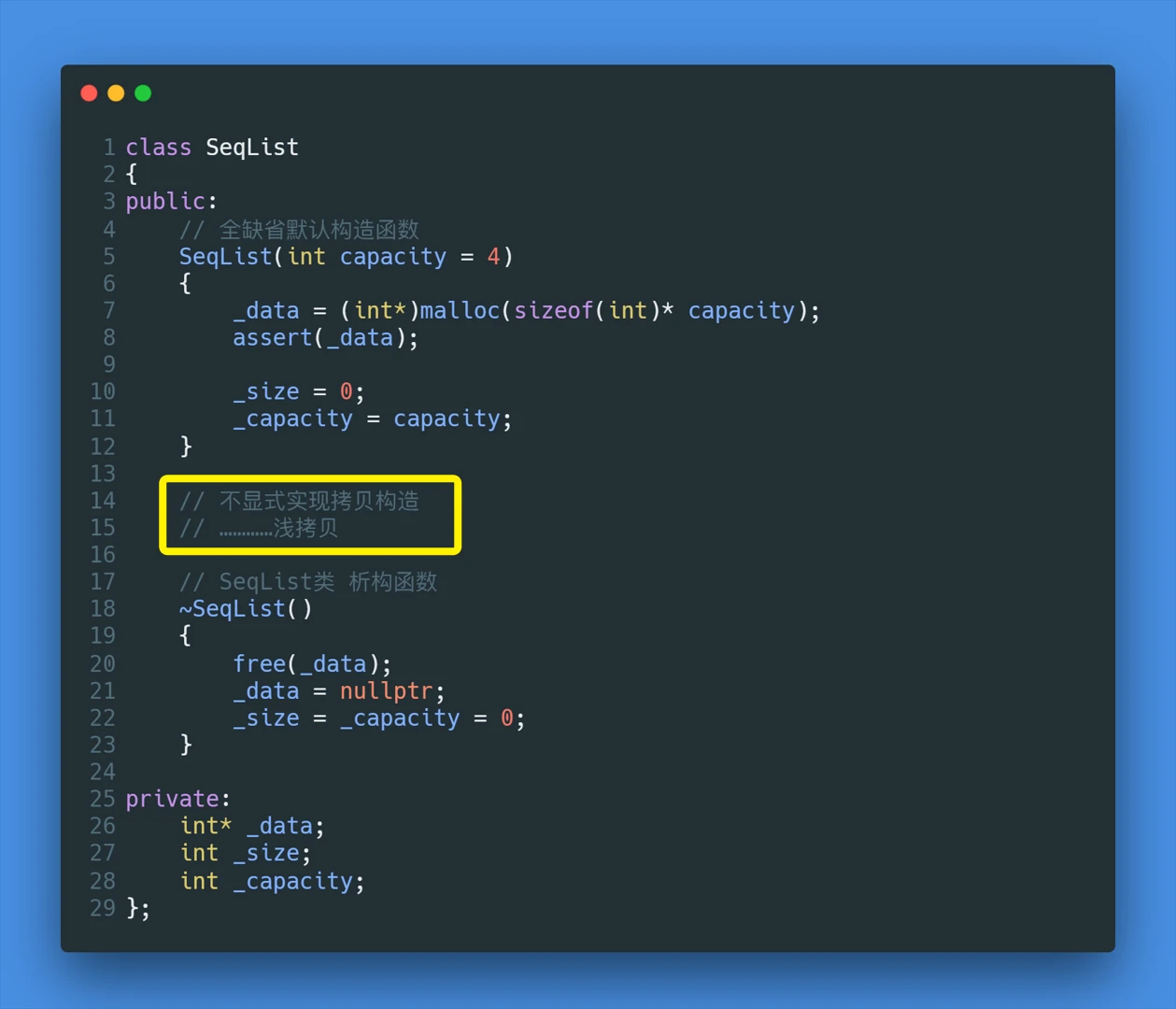
浅拷贝可以很好地完成一些类成员简单的拷贝构造. 但是对于 成员稍微复杂一点的类 使用浅拷贝就会发生一些问题比如,一个简单的 顺序表类
![]()
用这样的 对象实例化时,需要对成员进行
malloc申请内存的,使用浅拷贝会引发很严重的问题![]()
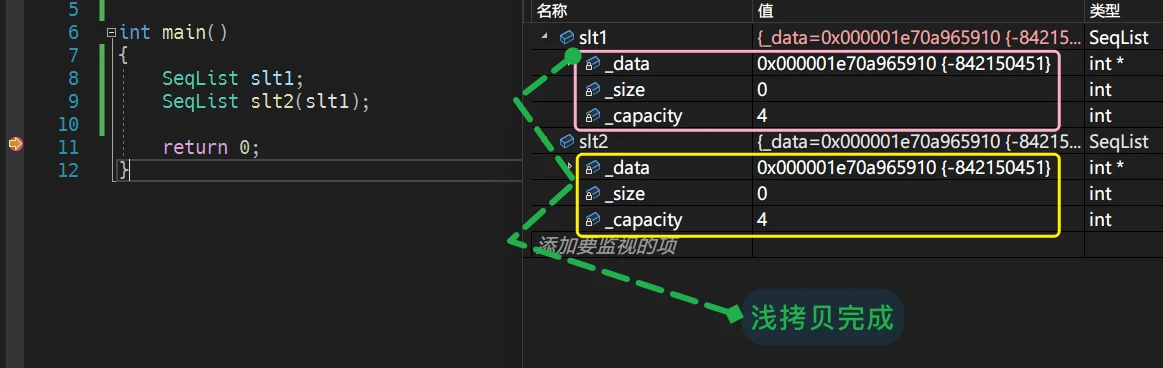
两个对象实例化完成,程序并没有出现问题,但是如果光标继续移动,
即将调用 析构函数![指针浅拷贝]() 指针浅拷贝
指针浅拷贝当
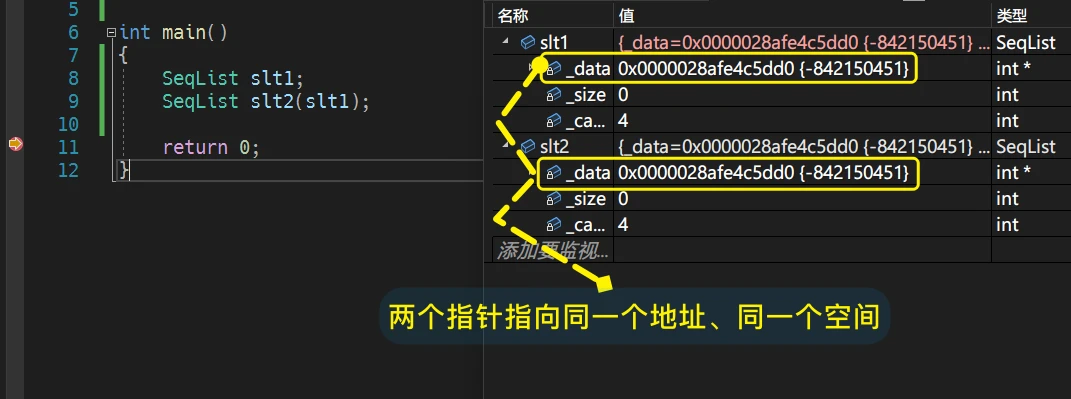
对象slt1调用析构函数时,程序崩溃了. 为什么会崩溃呢?原因很简单:当浅拷贝完成时,仔细看会发现 两个对象中的
_data指针成员指向了同一个地址,同一块空间![]()
而 对象调用
析构函数时,是需要free掉malloc出来的空间的,而两个指针指向同一块空间,就意味着要对同一块空间free两次. 这显然是无法实现的,所以程序崩溃了有关这类的问题,
浅拷贝都不能完美的解决,甚至不能解决。所以以后还有深拷贝


作者: 哈米d1ch 发表日期:2022 年 6 月 20 日